


摘要
從大模型技術(shù)發(fā)展趨勢(shì)出發(fā),分析了多模態(tài)、長(zhǎng)序列和混合專(zhuān)家模型的架構(gòu)特征和算力需求特點(diǎn)。圍繞大模型對(duì)巨量算力規(guī)模與復(fù)雜通信模式的需求,重點(diǎn)從算力利用效率、集群互聯(lián)技術(shù)兩方面量化分析了當(dāng)前大模型算力基礎(chǔ)設(shè)施存在的發(fā)展問(wèn)題和面臨的技術(shù)挑戰(zhàn),并提出了以應(yīng)用為導(dǎo)向、以系統(tǒng)為核心、以效率為目標(biāo)的高質(zhì)量算力基礎(chǔ)設(shè)施發(fā)展路徑。
關(guān)鍵詞:多模態(tài)模型;長(zhǎng)序列模型;混合專(zhuān)家模型;算力利用效率;集群互聯(lián);高質(zhì)量算力
引言
近年來(lái),生成式人工智能技術(shù),尤其是大語(yǔ)言模型(Large Language Model,LLM)的快速發(fā)展,標(biāo)志著人工智能進(jìn)入了一個(gè)前所未有的新時(shí)代。模型能力的提升和架構(gòu)的演進(jìn)催生了新的算力應(yīng)用范式,對(duì)所需的算力基礎(chǔ)設(shè)施提出了全新的挑戰(zhàn)。
1、大模型技術(shù)發(fā)展趨勢(shì)
1.1 大語(yǔ)言模型
最初的語(yǔ)言模型主要基于簡(jiǎn)單的統(tǒng)計(jì)方法,隨著深度學(xué)習(xí)技術(shù)的進(jìn)步,模型架構(gòu)逐步從循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Network,RNN)到長(zhǎng)短期記憶(Long Short Term Memory,LSTM)再到Transformer演進(jìn),模型的復(fù)雜性和能力相繼提升。2017年,Ashish Vaswani等首先提出了Transformer架構(gòu),這一架構(gòu)很快成為了大語(yǔ)言模型開(kāi)發(fā)的基石。2018年,BERT通過(guò)預(yù)訓(xùn)練加微調(diào)的方式,在多項(xiàng)自然語(yǔ)言處理任務(wù)上取得了前所未有的成效,極大地推動(dòng)了下游任務(wù)的發(fā)展和應(yīng)用。2018—2020年,OpenAI相繼發(fā)布了GPT-1、GPT-2和GPT-3,模型的參數(shù)量從1 億級(jí)別增長(zhǎng)到1 000 億級(jí)別,在多項(xiàng)自然語(yǔ)言處理任務(wù)上的性能呈現(xiàn)近似指數(shù)級(jí)的提升,論證了尺度定律(Scaling Law)在實(shí)際應(yīng)用中的效果。2022年底,ChatGPT發(fā)布之后,引發(fā)了一輪LLM熱潮,全球諸多企業(yè)、研究機(jī)構(gòu)短時(shí)間內(nèi)開(kāi)發(fā)出LLaMA、文心一言、通義千問(wèn)等上百種大語(yǔ)言模型。這一時(shí)期的模型大都基于Transformer基礎(chǔ)架構(gòu),利用大量的文本數(shù)據(jù)進(jìn)行訓(xùn)練,通過(guò)學(xué)習(xí)大規(guī)模數(shù)據(jù)集中的模式和關(guān)系,能夠執(zhí)行多種語(yǔ)言任務(wù)。但是,LLM的發(fā)展很快遇到了兩個(gè)顯著的問(wèn)題,一是模型的能力局限于對(duì)文本信息的理解和生成,實(shí)際的落地應(yīng)用場(chǎng)景受限;二是稠密模型架構(gòu)特征將會(huì)使得模型能力提升必然伴隨著算力需求的指數(shù)級(jí)增加,在算力資源受限的大背景下模型能力進(jìn)化的速度受限。
1.2 多模態(tài)模型
為了進(jìn)一步提升大模型的通用能力,研究者開(kāi)始探索模型在非文本數(shù)據(jù)(如圖像、視頻、音頻等領(lǐng)域)中的應(yīng)用,進(jìn)而發(fā)展出了多模態(tài)模型。這類(lèi)模型能夠處理和理解多種類(lèi)型的輸入數(shù)據(jù),實(shí)現(xiàn)跨模態(tài)的信息理解和生成。例如,OpenAI的GPT-4V模型可以理解圖片信息,而Google的BERT模型則被擴(kuò)展到VideoBERT用于理解視頻內(nèi)容。多模態(tài)模型的出現(xiàn)大大擴(kuò)展了人工智能的感知能力和應(yīng)用范圍,從簡(jiǎn)單的文本處理到復(fù)雜的視覺(jué)和聲音處理。多模態(tài)模型在基礎(chǔ)模型架構(gòu)上跟LLM一樣大都采用Transformer,但是通常需要設(shè)計(jì)特定的架構(gòu)來(lái)處理不同類(lèi)型的輸入數(shù)據(jù)。例如,它們可能結(jié)合了專(zhuān)門(mén)處理圖像數(shù)據(jù)的卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,CNN)組件,需要使用跨模態(tài)的注意力機(jī)制、聯(lián)合嵌入空間或特殊的融合層來(lái)實(shí)現(xiàn)對(duì)來(lái)自不同模態(tài)信息的有效融合。
1.3 長(zhǎng)序列模型
研究者們發(fā)現(xiàn)通過(guò)擴(kuò)展上下文窗口可以讓大模型能夠更好地捕捉全局信息,有助于更準(zhǔn)確地保留原文的語(yǔ)義、降低幻覺(jué)的發(fā)生、提高新任務(wù)的泛化能力,這就是提升大模型能力的另外一條有效的路徑——長(zhǎng)序列(Long Sequence)。2023年以來(lái),主流大模型都在不斷提高長(zhǎng)序列的處理能力(見(jiàn)圖1),比如GPT-4 Turbo可以處理長(zhǎng)達(dá)128 K的上下文,相比較GPT-3.5的4K處理能力已經(jīng)增長(zhǎng)了32倍,Anthropic的Claude2具備支持200 K上下文的潛力,Moonshot AI的Kimi Chat更是將中文文本處理能力提高到了2 000 K。從模型架構(gòu)上來(lái)看,傳統(tǒng)的LLM訓(xùn)練主要對(duì)Transformer中耗時(shí)最多的兩個(gè)核心單元——多頭注意力層(Multi-Head Attention,MHA)和前饋神經(jīng)網(wǎng)絡(luò)層(Feedforward Neural Network,F(xiàn)NN)進(jìn)行張量并行,但保留了歸一化層和丟棄層,這部分元素不需要大量的計(jì)算但隨著序列的長(zhǎng)度增加會(huì)產(chǎn)生大量的激活值內(nèi)存。由于這部分非張量并行的操作沿著序列維度是相互獨(dú)立的,可以通過(guò)沿序列維度切分實(shí)現(xiàn)激活值內(nèi)存的減少。然而,序列并行(Sequence Parallelism,SP)的增加會(huì)引入額外的全聚集(All Gather)通信操作。因此,長(zhǎng)序列的訓(xùn)練和推理會(huì)使得計(jì)算復(fù)雜度和難度提升,計(jì)算復(fù)雜度隨序列長(zhǎng)度n呈平方增加O(n2),模型需要引入新的并行層次和集合通信操作,從而導(dǎo)致端到端通信耗時(shí)占比增加,將會(huì)對(duì)模型算力利用率(Model FLOPS Utilization,MFU)產(chǎn)生影響。
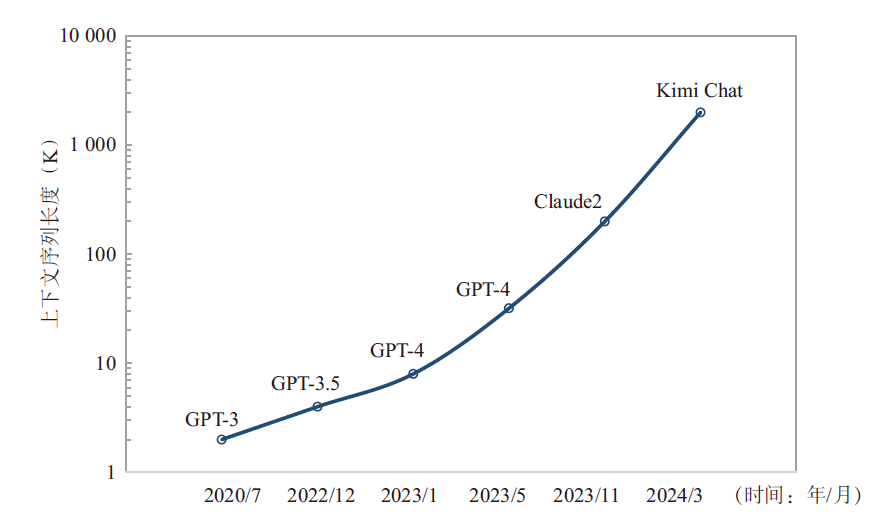
圖1 大模型上下文序列長(zhǎng)度發(fā)展趨勢(shì)
1.4 混合專(zhuān)家模型
為了在提高模型能力的同時(shí)能夠優(yōu)化算力開(kāi)銷(xiāo),研究者們選擇引入條件計(jì)算機(jī)制,即根據(jù)輸入有選擇地激活部分參數(shù)來(lái)進(jìn)行訓(xùn)練,這樣就使得整體計(jì)算開(kāi)銷(xiāo)隨模型參數(shù)量的增長(zhǎng)趨勢(shì)相對(duì)變緩,這就是混合專(zhuān)家(Mixture of Experts,MoE)模型的核心思想。MoE模型實(shí)際構(gòu)建了一種稀疏型的模型組件,將大型網(wǎng)絡(luò)分解為若干個(gè)“專(zhuān)家”子網(wǎng)絡(luò),每個(gè)專(zhuān)家擅長(zhǎng)處理特定類(lèi)型的信息或任務(wù),通過(guò)一個(gè)門(mén)控網(wǎng)絡(luò),在給定輸入時(shí)動(dòng)態(tài)選拔最適合的專(zhuān)家參與計(jì)算,這樣既可以減少不必要的計(jì)算量,也能提高模型的專(zhuān)業(yè)性和效率。Google早在2022年就發(fā)布了具有1.6 億參數(shù)的MoE模型Switch Transformer,包含2 048個(gè)專(zhuān)家,在同樣的FLOPS/Token的計(jì)算量下,Switch Transformer模型相比稠密型的T5-Base模型訓(xùn)練性能有7倍的提升。
MoE模型通過(guò)這種方式,在保持模型性能的同時(shí),相比同等規(guī)模的稠密模型顯著降低了計(jì)算資源的需求,在處理大規(guī)模數(shù)據(jù)和任務(wù)時(shí)表現(xiàn)出了更高的效率和可擴(kuò)展性。如今MoE模型已經(jīng)成為了業(yè)界大模型的發(fā)展趨勢(shì),2024年3月以來(lái),已經(jīng)先后出現(xiàn)了GPT4、Mixtral-8×7B、LLaMA-MoE、Grok-1、Qwen1.5-MoE、Jamba等10余種MoE模型。但是,MoE模型層的引入同時(shí)也帶來(lái)了額外的通信開(kāi)銷(xiāo),相比較LLM訓(xùn)練過(guò)程常用的張量并行、流水線(xiàn)并行和數(shù)據(jù)并行之外,MoE模型的訓(xùn)練引入了一種新的并行策略——專(zhuān)家并行(Expert Parallelism,EP),需要在MoE模型層前后分別增加一次多對(duì)多(All-to-All)通信操作,由此帶來(lái)了對(duì)硬件互聯(lián)拓?fù)浜屯ㄐ艓挼母咭蟆?/p>
根據(jù)上述分析,多模態(tài)、長(zhǎng)序列、MoE模型已經(jīng)成為大模型架構(gòu)演進(jìn)的確定性趨勢(shì),其中多模態(tài)、長(zhǎng)序列模型側(cè)重在模型能力側(cè)的提升,MoE模型兼顧模型能力的提升和算力利用效率的優(yōu)化。這種發(fā)展不僅提升了人工智能在內(nèi)容理解和內(nèi)容生成方面的能力,而且提高了模型的泛化能力和任務(wù)適應(yīng)性。然而,模型架構(gòu)的演進(jìn)同時(shí)帶來(lái)了更巨量的算力需求以及更復(fù)雜的集合通信需求,對(duì)現(xiàn)有算力基礎(chǔ)設(shè)施帶來(lái)了更大挑戰(zhàn)。
2、大模型算力基礎(chǔ)設(shè)施發(fā)展問(wèn)題與挑戰(zhàn)
2.1 可用算力規(guī)模亟需算力利用效率提升
業(yè)界先進(jìn)的(State-Of-The-Art,SOTA)模型參數(shù)規(guī)模和數(shù)據(jù)規(guī)模仍在持續(xù)增長(zhǎng),巨頭之爭(zhēng)已經(jīng)從千億模型向萬(wàn)億模型發(fā)展(見(jiàn)圖2),GPT-4模型具有1.8萬(wàn)億參數(shù),在約 13萬(wàn)億個(gè)Token上進(jìn)行了訓(xùn)練,算力需求大約為2.15e25 FLOPS,相當(dāng)于在大約2.5萬(wàn)張A100加速卡上運(yùn)行90~100天。為此,領(lǐng)先的科技公司正在加速算力基礎(chǔ)設(shè)施建設(shè),Meta在原有1.6萬(wàn)張A100卡集群基礎(chǔ)上又建設(shè)兩個(gè)具有約2.5萬(wàn)張H100加速卡集群,用來(lái)加速LLaMA3的訓(xùn)練;Google建設(shè)了具有2.6萬(wàn)張H100加速卡的A3人工智能超級(jí)計(jì)算機(jī),可以提供26 ExaFLOPS的人工智能性能,Microsoft和OpenAI正在為GPT-6訓(xùn)練構(gòu)建具有10萬(wàn)張H100加速卡集群,并規(guī)劃具有數(shù)百萬(wàn)張卡的“星際之門(mén)”人工智能超算。由此可見(jiàn),萬(wàn)卡已經(jīng)成為未來(lái)先進(jìn)大模型訓(xùn)練的新起點(diǎn)。
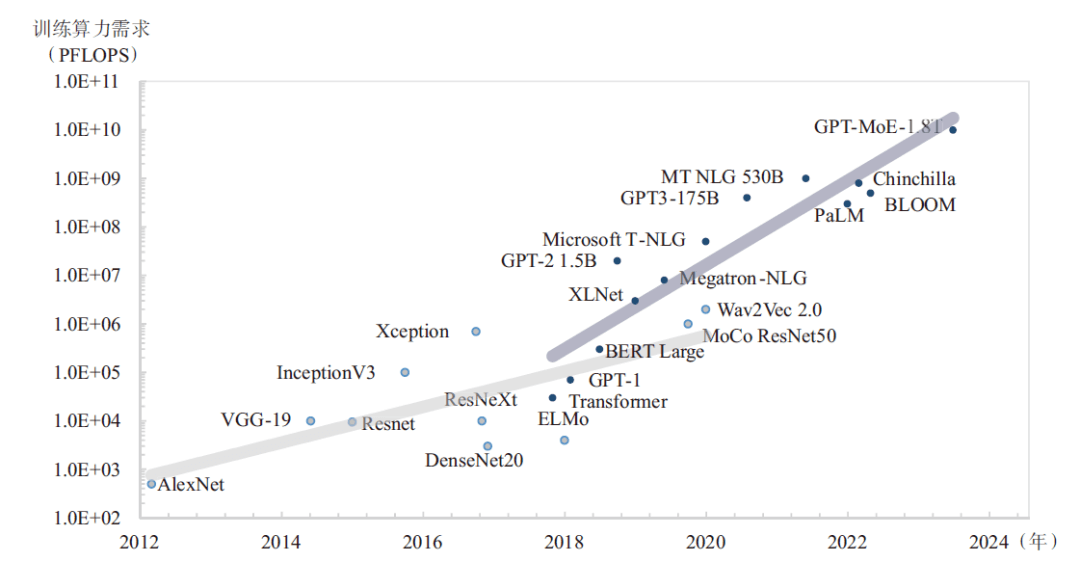
圖2 大模型算力需求發(fā)展趨勢(shì)
隨著算力需求持續(xù)增加、算力規(guī)模持續(xù)擴(kuò)大,算力利用效率問(wèn)題日益凸顯。據(jù)公開(kāi)報(bào)道,GPT-4訓(xùn)練的MFU在32%~36%之間,其根本原因是顯存帶寬限制了芯片算力的發(fā)揮,即“內(nèi)存墻”(Memory Wall)問(wèn)題。在LLM模型的訓(xùn)練過(guò)程中,模型參數(shù)、梯度、中間狀態(tài)、激活值都需要存放在顯存當(dāng)中,并且需要頻繁地傳輸參數(shù)和梯度信息以進(jìn)行參數(shù)的更新。高顯存帶寬可以加快參數(shù)和梯度數(shù)據(jù)的傳輸速度,從而提高參數(shù)更新的效率,加速模型收斂的速度。因此,用于人工智能訓(xùn)練的高端加速卡會(huì)選用最先進(jìn)的高帶寬內(nèi)存(High Bandwidth Memory,HBM)作為顯存,以求最大化數(shù)據(jù)傳輸速度,增加計(jì)算時(shí)間占比,從而獲得更高的算力利用效率。
從宏觀(guān)技術(shù)發(fā)展趨勢(shì)上看,在過(guò)去20年間芯片的算力峰值以每2年3倍的速度增長(zhǎng),但是內(nèi)存的帶寬增長(zhǎng)速度只有1.6倍[11]。內(nèi)存的性能提升速度遠(yuǎn)低于處理器的性能提升速度,這就使得芯片計(jì)算力和運(yùn)載力之間的剪刀差越來(lái)越大,僅通過(guò)增加處理器數(shù)量和核心數(shù),也無(wú)法有效提高整體的計(jì)算能力。為此,NVIDIA從V100開(kāi)始,在每一代芯片中間都會(huì)有一次顯存升級(jí),以A100為例,首發(fā)版本采用40 G HBM2顯存,帶寬最高1 555 GB/s,升級(jí)版本采用80 G HBM2,帶寬提升至2 039 GB/s,但這帶來(lái)的算力利用效率和應(yīng)用性能提升效果有限,A100 80 G在Bert-Large微調(diào)場(chǎng)景下性能提升僅14%(見(jiàn)圖3)。
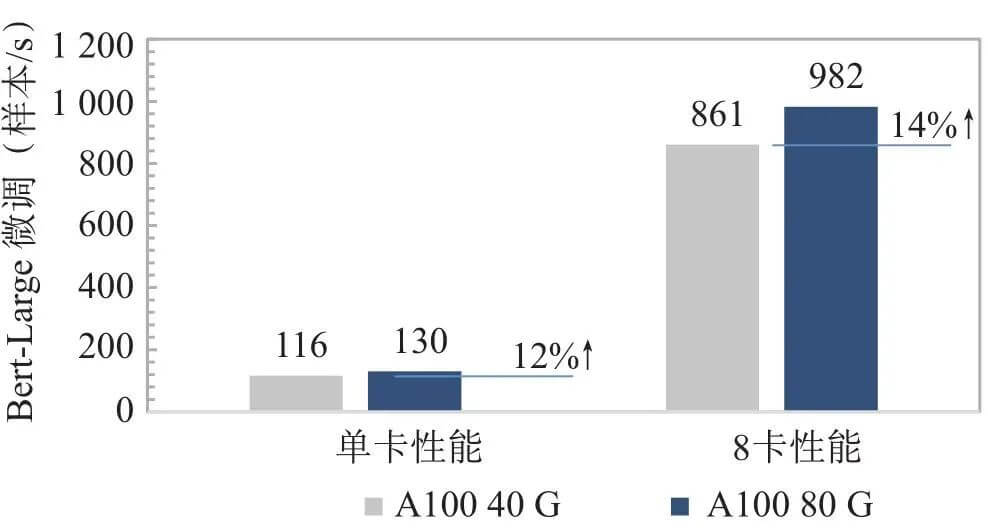
圖3 相同算力下不同顯存帶寬A100模型性能對(duì)比
為了能夠量化顯存帶寬對(duì)芯片算力利用效率的影響,采用具有相同顯存(容量96 G、帶寬2.45 TB/s)、不同算力的人工智能加速卡,在具有不同參數(shù)規(guī)模大小的LLM模型預(yù)訓(xùn)練場(chǎng)景中進(jìn)行了算力效率的實(shí)測(cè)。如圖4(a)所示,在使用BF16算力精度訓(xùn)練LLaMA-7B模型的過(guò)程中,BF16算力利用率隨芯片算力的降低而顯著增加,對(duì)于具有443 TFLOPS算力值的芯片而言,其算力利用率只有54%,而具有148 TFLOPS算力的芯片,算力利用率達(dá)到了71.3%,這意味著顯存帶寬限制了高算力芯片的算力利用效率。同樣的規(guī)律也反映在了LLaMA-13B和GPT-22B等更大參數(shù)規(guī)模的模型預(yù)訓(xùn)練實(shí)測(cè)結(jié)果中。如圖4(b)所示,當(dāng)標(biāo)稱(chēng)BF16性能從148 TFLOPS增加到298 TFLOPS,即標(biāo)稱(chēng)算力增加2倍的情況下,可用算力增加僅1.8倍,或者說(shuō)算力損失29.6%;當(dāng)BF16性能進(jìn)一步從298 TFLOPS繼續(xù)增加到443 TFLOPS,即標(biāo)稱(chēng)算力增加48.8%的情況下,可用算力性能僅增加22.4%,算力損失高達(dá)42.1%。由此可以推斷,算力性能進(jìn)一步提高所帶來(lái)的可用算力收益會(huì)由于顯存帶寬的限制呈現(xiàn)邊際遞減,即GPT-4訓(xùn)練的MFU只有不到40%的原因。可以看出,“內(nèi)存墻”是限制當(dāng)前可用AI算力擴(kuò)展的最大瓶頸。
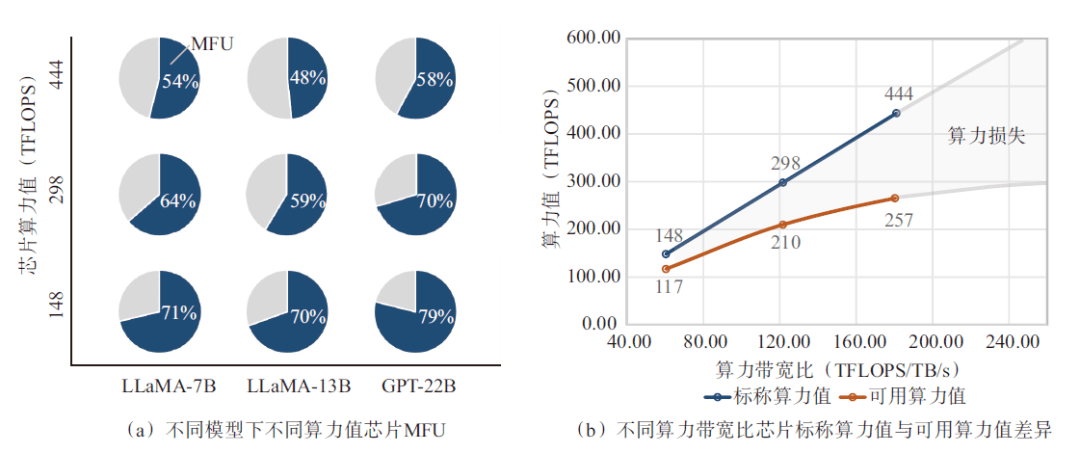
圖4 顯存帶寬對(duì)算力利用效率影響
2.2 集群性能提升依賴(lài)跨尺度、多層次互聯(lián)
在尺度定律的驅(qū)動(dòng)下,SOTA模型的參數(shù)量以每2年410倍的速度增長(zhǎng)、算力需求以每2年750倍的速度增長(zhǎng),遵循“摩爾定律”的硬件算力增長(zhǎng)速度和顯存容量增長(zhǎng)速度遠(yuǎn)遠(yuǎn)無(wú)法滿(mǎn)足模型訓(xùn)練的需求。因此,構(gòu)建多芯互聯(lián)集群成為大模型技術(shù)發(fā)展的必經(jīng)之路,能夠支持SOTA模型訓(xùn)練集群的規(guī)模也在短時(shí)間內(nèi)從千卡向萬(wàn)卡發(fā)展,集群性能的實(shí)現(xiàn)將會(huì)受到顯存帶寬、卡間互聯(lián)帶寬、節(jié)點(diǎn)間互聯(lián)帶寬、互聯(lián)拓?fù)洹⒕W(wǎng)絡(luò)架構(gòu)、通信庫(kù)設(shè)計(jì)、軟件和算法等多重因素影響,大規(guī)模加速計(jì)算集群的構(gòu)建已經(jīng)演變成為跨尺度、多層次的復(fù)雜系統(tǒng)工程問(wèn)題。
從應(yīng)用層面來(lái)看,大模型訓(xùn)練往往需要通過(guò)有機(jī)的組合多種分布式策略,來(lái)有效地緩解LLM訓(xùn)練過(guò)程中的硬件限制。對(duì)于基于Transformer架構(gòu)的模型來(lái)說(shuō),常用的分布式策略包括數(shù)據(jù)并行、張量并行和流水線(xiàn)并行,各自的實(shí)現(xiàn)方式和所引入的集合通信操作有所不同。其中,數(shù)據(jù)并行和流水線(xiàn)并行的通信計(jì)算比不高,通常發(fā)生在計(jì)算節(jié)點(diǎn)之間。張量并行的核心思想是對(duì)Transformer Block中的兩個(gè)核心單元——多頭自注意力層和前饋神經(jīng)網(wǎng)絡(luò)層進(jìn)行拆分,其中多頭自注意力層按照不同的頭進(jìn)行并行拆分,而前饋神經(jīng)網(wǎng)絡(luò)層按照權(quán)重進(jìn)行并行拆分。使用張量并行時(shí),每個(gè)Transformer Block將在前向計(jì)算和反向傳播時(shí)分別引入兩次額外的All Reduce通信操作。與數(shù)據(jù)并行相比,張量并行具有更高的通信計(jì)算比,這意味著張量并行算法對(duì)計(jì)算設(shè)備間的通信帶寬需求更高。因此,在實(shí)際應(yīng)用中,一般把張量并行算法限制在單個(gè)計(jì)算節(jié)點(diǎn)內(nèi)。如前文所述,隨著大模型進(jìn)一步向多模態(tài)、長(zhǎng)序列、混合專(zhuān)家架構(gòu)演進(jìn),分布式策略也隨之更加復(fù)雜,序列并行和專(zhuān)家并行的引入,也帶來(lái)了更多All Gather和All-to-All通信操作,與張量并行類(lèi)似,需要計(jì)算設(shè)備間超低延遲、超高帶寬的通信能力,從而進(jìn)一步提高對(duì)單個(gè)計(jì)算節(jié)點(diǎn)或者說(shuō)計(jì)算域的性能要求。
從硬件層面來(lái)看,互聯(lián)的設(shè)計(jì)一方面需要滿(mǎn)足算力高效擴(kuò)展的需求,另一方面還要匹配并行訓(xùn)練集合通信對(duì)互聯(lián)拓?fù)涞囊蟆;ヂ?lián)設(shè)計(jì)可以按尺度分為片上互聯(lián)、片間互聯(lián)和節(jié)點(diǎn)間互聯(lián)。片上互聯(lián)物理尺度最小、技術(shù)難度較高,需要采用芯粒(Chiplet)技術(shù)將多個(gè)Chiplet進(jìn)行合封并建立超高速互聯(lián)鏈路,領(lǐng)先的芯片廠(chǎng)商AMD、Intel、NVIDIA、壁仞科技等公司的產(chǎn)品都采用相關(guān)技術(shù)。以NVIDIA的B100芯片為例,由于逼近光刻工藝極限,芯片單位面積計(jì)算能力較上代只有14%提升,性能的進(jìn)一步提升只能通過(guò)增加硅面積,但這又受到掩膜極限的限制。于是,NVIDIA在盡可能做大單晶粒面積的基礎(chǔ)上,通過(guò)更先進(jìn)的基片上芯片(Chip on Wafer on Substrate,CoWoS)工藝將兩個(gè)晶粒整合到一個(gè)封裝當(dāng)中,之間通過(guò)10 TB/s NVLink進(jìn)行互聯(lián),使得兩個(gè)芯片可以作為一個(gè)統(tǒng)一計(jì)算設(shè)備架構(gòu)(Compute Unified Device Architecture,CUDA)在GPU運(yùn)行。由此可見(jiàn),在當(dāng)前工藝極限和掩膜極限下,通過(guò)先進(jìn)封裝和高速晶粒對(duì)晶粒互聯(lián)可以進(jìn)一步推動(dòng)芯片性能提高,但是這條技術(shù)路線(xiàn)的封裝良率和高昂成本也將會(huì)極大限制最新芯片的產(chǎn)能,影響芯片的可獲得性。
相比片上互聯(lián),片間互聯(lián)的技術(shù)成熟度更高、可獲得性更優(yōu),通常這部分互聯(lián)發(fā)生在單一節(jié)點(diǎn)或超節(jié)點(diǎn)內(nèi)部,旨在構(gòu)建多卡之間超高帶寬、超低延遲的計(jì)算域,來(lái)滿(mǎn)足張量并行、專(zhuān)家并行和序列并行極高的通信需求。目前,已經(jīng)有NVLink、PCIe、RoCE(RDMA over Converged Ethernet)以及諸多私有互聯(lián)方案。從互聯(lián)速率來(lái)看,NVIDIA第5代NVLink單Link雙向帶寬從第4代NVLink的50 GB/s升級(jí)到100 GB/s,也就是說(shuō)B100/B200片間互聯(lián)雙向帶寬最高可以達(dá)到1 800 GB/s,AMD的Infinity Fabric最大可以支持112 GB/s 點(diǎn)對(duì)點(diǎn)(Peer-to-Peer,P2P)互聯(lián)帶寬。從互聯(lián)拓?fù)湫螒B(tài)來(lái)看,片間互聯(lián)可以分為直連拓?fù)浜徒粨Q拓?fù)鋬纱箢?lèi),直連拓?fù)涞耐ㄓ眯愿鼜?qiáng)、協(xié)議兼容性更高,如AMD MI300X、Intel Gaudi、寒武紀(jì)MLU系列等開(kāi)放加速規(guī)范模組(OCP Accelerator Module,OAM)形態(tài)加速卡可以通過(guò)通用加速器基板(Universal Baseboard,UBB)實(shí)現(xiàn)8卡全互聯(lián),NVIDIA H100 NVL、AMD MI210、Intel Gaudi3(HL-338)等PCIe形態(tài)加速卡則可以通過(guò)橋接器實(shí)現(xiàn)2卡或4卡互聯(lián),直連拓?fù)涞膯?wèn)題在于片間互聯(lián)均分每卡的輸入/輸出(Input/Output,I/O)總帶寬,導(dǎo)致任意兩卡間P2P互聯(lián)帶寬較低,互聯(lián)帶寬的提升依賴(lài)于SerDes速率的升級(jí),相較算力提升速度滯后。交換拓?fù)湫枰诮粨Q機(jī)(Switch)交換芯片,目前主流芯片廠(chǎng)商中只有NVIDIA提供基于NVSwitch的互聯(lián)方案,所有GPU的縱向擴(kuò)展(Scale-up)端口直連到NVSwitch以實(shí)現(xiàn)全帶寬、All to All互聯(lián)形態(tài),這也是NVLink帶寬遠(yuǎn)高于直連拓?fù)浞桨傅脑颉N磥?lái),隨著單卡算力的提升以及單節(jié)點(diǎn)內(nèi)加速卡數(shù)量提升,基于Switch芯片構(gòu)建更高帶寬、更大規(guī)模的GPU互聯(lián)域?qū)⒊蔀橐环N趨勢(shì),但是如何實(shí)現(xiàn)Scale-up網(wǎng)絡(luò)的延遲優(yōu)化、擁塞控制、負(fù)載均衡以及在網(wǎng)計(jì)算也將成為新的挑戰(zhàn)。
節(jié)點(diǎn)間橫向擴(kuò)展(Scale-out)互聯(lián)作用主要是為參數(shù)面網(wǎng)絡(luò)中流水線(xiàn)并行和數(shù)據(jù)并行提供足夠通信帶寬,通常采用Infiniband或RoCE組成胖樹(shù)(Fat-Tree)無(wú)阻塞網(wǎng)絡(luò)架構(gòu),二者都能夠通過(guò)多層組網(wǎng)實(shí)現(xiàn)千卡乃至萬(wàn)卡級(jí)集群互聯(lián),比如采用64端口交換機(jī),通過(guò)3層Fat-Tree無(wú)阻塞組網(wǎng)理論上可以構(gòu)建約6.6萬(wàn)卡集群,采用128端口交換機(jī)理論上可以構(gòu)建約52.4萬(wàn)卡集群。從節(jié)點(diǎn)側(cè)來(lái)看,Scale-out的設(shè)計(jì)分為外置網(wǎng)絡(luò)控制器和集成網(wǎng)絡(luò)控制器兩種類(lèi)型,外置網(wǎng)絡(luò)控制器方案通用性更強(qiáng),PCIe標(biāo)準(zhǔn)形態(tài)的網(wǎng)絡(luò)控制器通常會(huì)按1∶1或者1∶2的比例與加速卡連接到同一顆PCIe Switch芯片上以實(shí)現(xiàn)最短的Scale-out路徑,可以根據(jù)現(xiàn)有數(shù)據(jù)中心網(wǎng)絡(luò)基礎(chǔ)設(shè)施設(shè)計(jì)來(lái)靈活選擇與之相匹配的網(wǎng)絡(luò)控制器類(lèi)型和數(shù)量組成遠(yuǎn)程直接內(nèi)存訪(fǎng)問(wèn)(Remote Direct Memory Access,RDMA)網(wǎng)絡(luò)方案,支持Infiniband卡、以太網(wǎng)卡以及定制智能網(wǎng)卡。集成網(wǎng)絡(luò)控制器方案將網(wǎng)絡(luò)控制器直接集成到加速卡芯片當(dāng)中,比較有代表性的如Intel Gaudi系列,Gaudi2每顆芯片支持直出300 Gbit/s Ethernet Scale-out鏈路,Gaudi3將帶寬進(jìn)行了翻倍升級(jí)達(dá)到600 Gbit/s,計(jì)算和網(wǎng)絡(luò)的同步在芯片內(nèi)完成,無(wú)需主機(jī)干預(yù),可以進(jìn)一步減小延遲。數(shù)據(jù)中心內(nèi)部的節(jié)點(diǎn)間互聯(lián)方案已經(jīng)相對(duì)成熟,但隨著GPU集群建設(shè)規(guī)模的不斷擴(kuò)大,節(jié)點(diǎn)間互聯(lián)方案的成本和能耗也在不斷提升,在中等規(guī)模集群當(dāng)中占比已達(dá)15%~20%。因此,需要面向?qū)嶋H應(yīng)用需求,平衡性能、成本、能耗三大要素,最終實(shí)現(xiàn)全局最優(yōu)的節(jié)點(diǎn)間互聯(lián)方案設(shè)計(jì)。此外,大模型頭部公司正在規(guī)劃的具有百萬(wàn)卡級(jí)的集群,已經(jīng)超出現(xiàn)有網(wǎng)絡(luò)架構(gòu)可擴(kuò)展極限,而單一數(shù)據(jù)中心無(wú)法同時(shí)為如此規(guī)模的卡提供足夠的電力支撐。未來(lái),超大規(guī)模跨域無(wú)損算力網(wǎng)絡(luò)將會(huì)是支撐更大規(guī)模模型訓(xùn)練的關(guān)鍵。
綜上,隨著大模型算力需求的增長(zhǎng),加速集群互聯(lián)技術(shù)已經(jīng)演變成為跨尺度、多層次的復(fù)雜系統(tǒng)工程問(wèn)題,涉及芯片設(shè)計(jì)、先進(jìn)封裝、高速電路、互聯(lián)拓?fù)洹⒕W(wǎng)絡(luò)架構(gòu)、傳輸技術(shù)等多學(xué)科和工程領(lǐng)域,需要以系統(tǒng)為核心,自上而下軟硬協(xié)同設(shè)計(jì)才能獲得最優(yōu)的集群性能。
3、大模型算力基礎(chǔ)設(shè)施高質(zhì)量發(fā)展路徑
隨著SOTA大模型訓(xùn)練算力起點(diǎn)從千卡向萬(wàn)卡乃至更大規(guī)模演進(jìn),能源逐漸成為大模型發(fā)展遇到的主要瓶頸,在算力資源和電力資源的雙重限制下,未來(lái)大模型的軍備競(jìng)賽將會(huì)從“算力之爭(zhēng)”演變?yōu)?ldquo;效率之爭(zhēng)”,優(yōu)化算力供給結(jié)構(gòu),發(fā)展具有高算效、高能效、可持續(xù)、可獲得、可評(píng)估五大特征的高質(zhì)量算力已經(jīng)成為當(dāng)務(wù)之急。
算力效率的提升要圍繞算力的生產(chǎn)、聚合、調(diào)度、釋放形成一個(gè)完整的技術(shù)體系。在算力生產(chǎn)環(huán)節(jié),算力和顯存帶寬的設(shè)計(jì)失衡往往是導(dǎo)致算力效率損失的主要因素。因此,芯片“算力-顯存”協(xié)同設(shè)計(jì)至關(guān)重要,需要以算力效率為目標(biāo)來(lái)平衡芯片的計(jì)算能力和顯存的運(yùn)載能力,避免顯存帶寬約束下的巨大算力損失。在算力聚合環(huán)節(jié),通過(guò)“算力-互聯(lián)”協(xié)同設(shè)計(jì)和“算力-網(wǎng)絡(luò)”協(xié)同設(shè)計(jì),采用高、低速域分層互聯(lián)架構(gòu),為芯片匹配合適的片間互聯(lián)和節(jié)點(diǎn)間互聯(lián)帶寬,解決通信性能瓶頸,可以進(jìn)一步提升芯片在實(shí)際業(yè)務(wù)模型下的MFU,提升集群層面投資回報(bào)率。在算力調(diào)度環(huán)節(jié),通過(guò)全面的監(jiān)控指標(biāo)和異常檢測(cè)快速定位軟硬件故障,通過(guò)斷點(diǎn)續(xù)訓(xùn)、故障容錯(cuò)等機(jī)制快速恢復(fù)訓(xùn)練,實(shí)現(xiàn)大模型長(zhǎng)時(shí)間穩(wěn)定訓(xùn)練,以此提升集群算力整體利用率,降低大模型整體訓(xùn)練成本。在算力釋放環(huán)節(jié),兼容主流生態(tài),支持業(yè)界主流框架、算法和計(jì)算精度,能夠在最短時(shí)間內(nèi)利用最新的精度優(yōu)化、顯存優(yōu)化以及通信優(yōu)化上的算法創(chuàng)新成果發(fā)掘出有限算力的最大價(jià)值。
能源利用效率的提升需要以節(jié)能為目標(biāo),開(kāi)展面向應(yīng)用、軟硬協(xié)同的集群方案設(shè)計(jì),在高算效服務(wù)器系統(tǒng)硬件基礎(chǔ)上,通過(guò)匹配實(shí)際可用算力規(guī)模的網(wǎng)絡(luò)方案實(shí)現(xiàn)設(shè)計(jì)層面的集群功耗優(yōu)化。進(jìn)一步,通過(guò)部件、系統(tǒng)、機(jī)柜、數(shù)據(jù)中心多層級(jí)先進(jìn)液冷技術(shù)的應(yīng)用,結(jié)合供電、散熱、制冷、管理一體化設(shè)計(jì)實(shí)現(xiàn)部署層面的能效提升,最終獲得全局最優(yōu)電源使用效率(Power Usage Effectiveness,PUE)。
此外,大模型算力基礎(chǔ)設(shè)施已經(jīng)成為推動(dòng)信息產(chǎn)業(yè)核心技術(shù)發(fā)展的重要驅(qū)動(dòng)力,需要聚攏核心部件、專(zhuān)用芯片、電子元器件、基礎(chǔ)軟件、應(yīng)用軟件等國(guó)內(nèi)外產(chǎn)業(yè)鏈領(lǐng)先技術(shù)方案,加速構(gòu)建分層解耦、多元開(kāi)放、標(biāo)準(zhǔn)統(tǒng)一的產(chǎn)業(yè)鏈生態(tài),降低對(duì)單一技術(shù)路線(xiàn)的依賴(lài)、避免煙囪式發(fā)展,通過(guò)產(chǎn)業(yè)鏈協(xié)同創(chuàng)新實(shí)現(xiàn)可持續(xù)算力演進(jìn)和算力產(chǎn)業(yè)的健康發(fā)展。持續(xù)推動(dòng)算力基建化,采用融合架構(gòu),通過(guò)硬件重構(gòu)實(shí)現(xiàn)多元異構(gòu)算力資源池化,提供多元、彈性、可伸縮擴(kuò)展的算力聚合能力,通過(guò)軟件定義實(shí)現(xiàn)資源池的智能高效管理,提供更高效、更便捷的算力調(diào)度能力,降低多元算力的使用門(mén)檻,實(shí)現(xiàn)算力普適普惠。最后,還需要建立以應(yīng)用為導(dǎo)向、以效率為目標(biāo)、全面科學(xué)的高質(zhì)量算力評(píng)估標(biāo)準(zhǔn),推動(dòng)算力供給結(jié)構(gòu)優(yōu)化,促進(jìn)算力產(chǎn)業(yè)良性發(fā)展。
?結(jié)束語(yǔ)
在市場(chǎng)、資本、政策的聯(lián)合驅(qū)動(dòng)下,大模型快速向多模態(tài)、長(zhǎng)序列、混合專(zhuān)家形態(tài)演進(jìn),參數(shù)量更加龐大、模型架構(gòu)日益復(fù)雜,從而帶來(lái)對(duì)更大規(guī)模算力和更復(fù)雜通信模式的需求。然而,算存失衡發(fā)展嚴(yán)重限制了算力利用效率,并帶來(lái)了巨大的算力資源損失,實(shí)際可用算力規(guī)模增速難以滿(mǎn)足應(yīng)用發(fā)展需求。隨著集群規(guī)模從千卡向萬(wàn)卡發(fā)展,跨尺度、多層次互聯(lián)技術(shù)將成為未來(lái)集群性能擴(kuò)展效率的關(guān)鍵。在算力和電力資源的雙重限制下,大模型軍備競(jìng)賽正在向效率之爭(zhēng)快速轉(zhuǎn)變,亟需圍繞算力生產(chǎn)、聚合、調(diào)度、釋放四大環(huán)節(jié)構(gòu)建高算效實(shí)現(xiàn)的完整技術(shù)體系,從集群設(shè)計(jì)和數(shù)據(jù)中心部署層面實(shí)現(xiàn)更高能效,最終形成可持續(xù)、可獲得、可評(píng)估的高質(zhì)量算力。
來(lái)源:信息通信技術(shù)與政策



